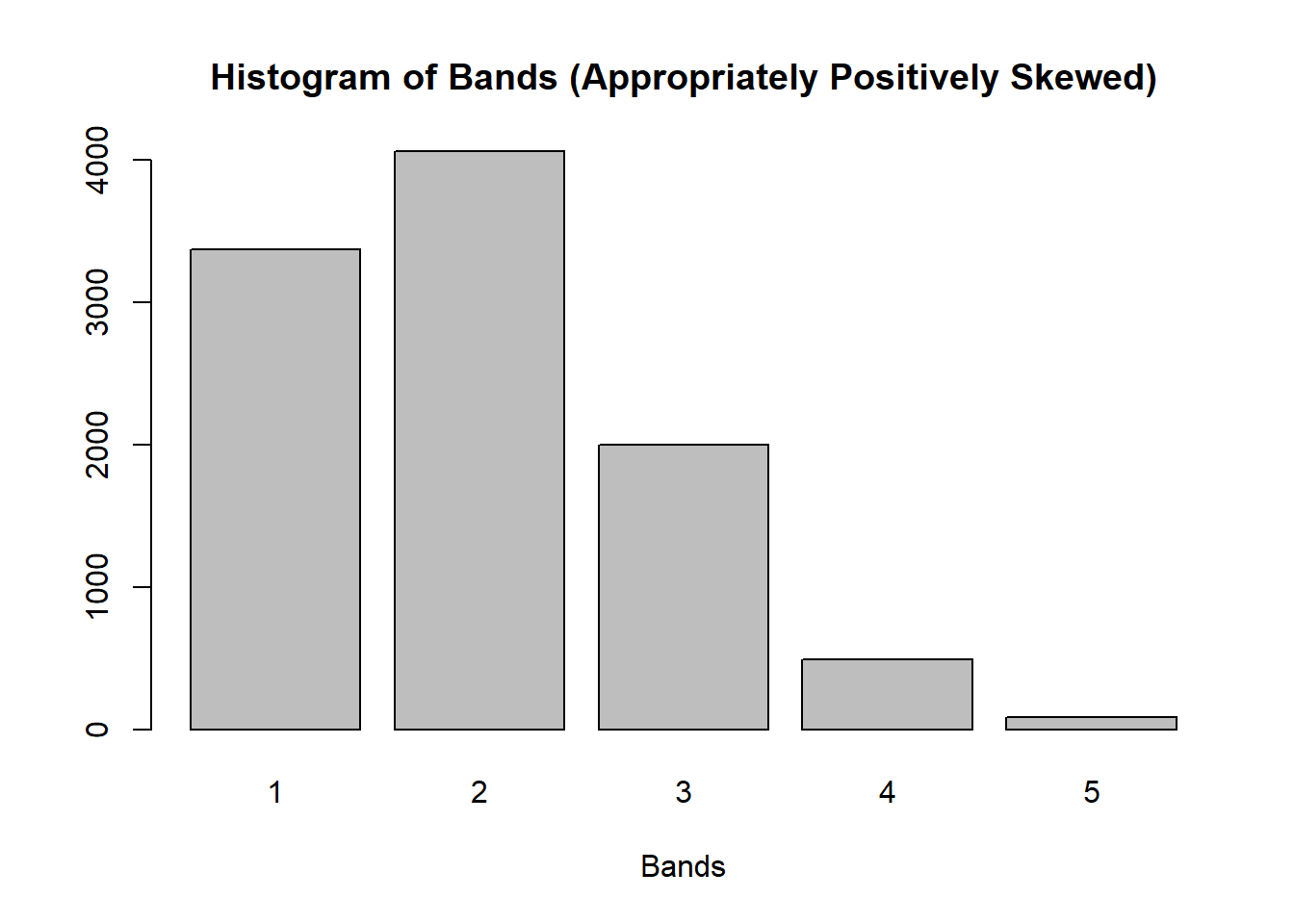Simulation is the scientific process of creating an hypothetical situation that mirrors the real world phenomenon. In this article, we shall explore a few ways of generating hypothetical variables that closely resemble the data that may, for instance, be collected in a field survey. You may have asked yourself how a researcher can go about generating age values of a population without actually asking the respondents in a sample of the given population to fill a survey questionnaire asking for their ages. So, this is how.
Different variables require different approaches of simulation, because of the underlying probability distribution. Simply put, a probability distribution defines the pattern to which the values of a variable conform. There is always a pattern that values follow, and for us to generate (simulate) the values of a variable, we are required to know what this pattern looks like in advance. This prior knowledge of the characteristics of the pattern is known as apriori information, because we know it in advance largely by reading the literature. For example, if we want to simulate 100 age values from a population of epileptics, we need to ask these two questions:-
What is the usual pattern of age like for the general population? We can use a histogram to get a hint of the underlying probability distribution for age. If the histogram reveals a bell-shaped pattern, we can roughly consider the normal distribution as the underlying probability distribution. There are many other probability distributions, and normal distribution is just one of them, which also happens to be the most common for numerical variables in the field of real numbers (x ∈ ℝ).
What is the mean and standard deviation of the age of epileptics? The answer will allow us to reproduce the histogram in (2) above without going to the field to collect actual age data. Here, mean and standard deviation are the only parameters whose apriori values ae required.
In this article, we shall simulate variables whose values mirror the data for the means testing instrument (MTI) used by the Government of Kenya to place university students into 5 bands for award of scholarships. This follows from my earlier article on using artificial intelligence as a more reliable alternative to the new MTI-based university funding model in Kenya.
Disclaimer!
The data is simulated, and therefore substantially differs with the actual scenario! The data is for learning purposes only, and the statistical estimates reported MUST NOT be taken as true reflection of the real-word situation.
2 Literature
There are a number of factors1 that the new MTI-based university funding model in Kenya considers for placement of students into the 5 bands. We shall discuss each one of them and deduce the probable underlying probability distributions and their associated parametric values that will enable us to simulate these factors. We shall simulate the data for 10000 students, thus x_i where i = 1, 2, 3, ..., 10000. Because the values are randomly generated, we shall seed the random number generator (RNG), for reproducibility purposes, with the arbitrary value of 44. Note that there is no real reason for this choice.
2.1 Bands
This is the outcome – a categorical 5-point ordinal variable where 1 represents the most needy and 5 represents the least needy2, thus x_{ij} where j = \{1, 2, 3, ..., 5\}. We will assume that the first 2 or 3 bands have a fairly higher chance of occurring compared to the last bands, i.e for the i^{th} student, p(x_{i1}) > p(x_{i2}) >... >p(x_{i5}). We need a probability distribution function that draws 5 numbers between 1 to 5 for 10000 observations. A multinomial distribution will do just that. We simply need to specify n = 1 (create 1 vector), size = 10000 (number of observations), and prob = p(x_{ij}) (vector of probabilities) in the function rmultinom from the package {stats}. The function is the Application Programming Interface (API) to the RNG for multinomial distribution.
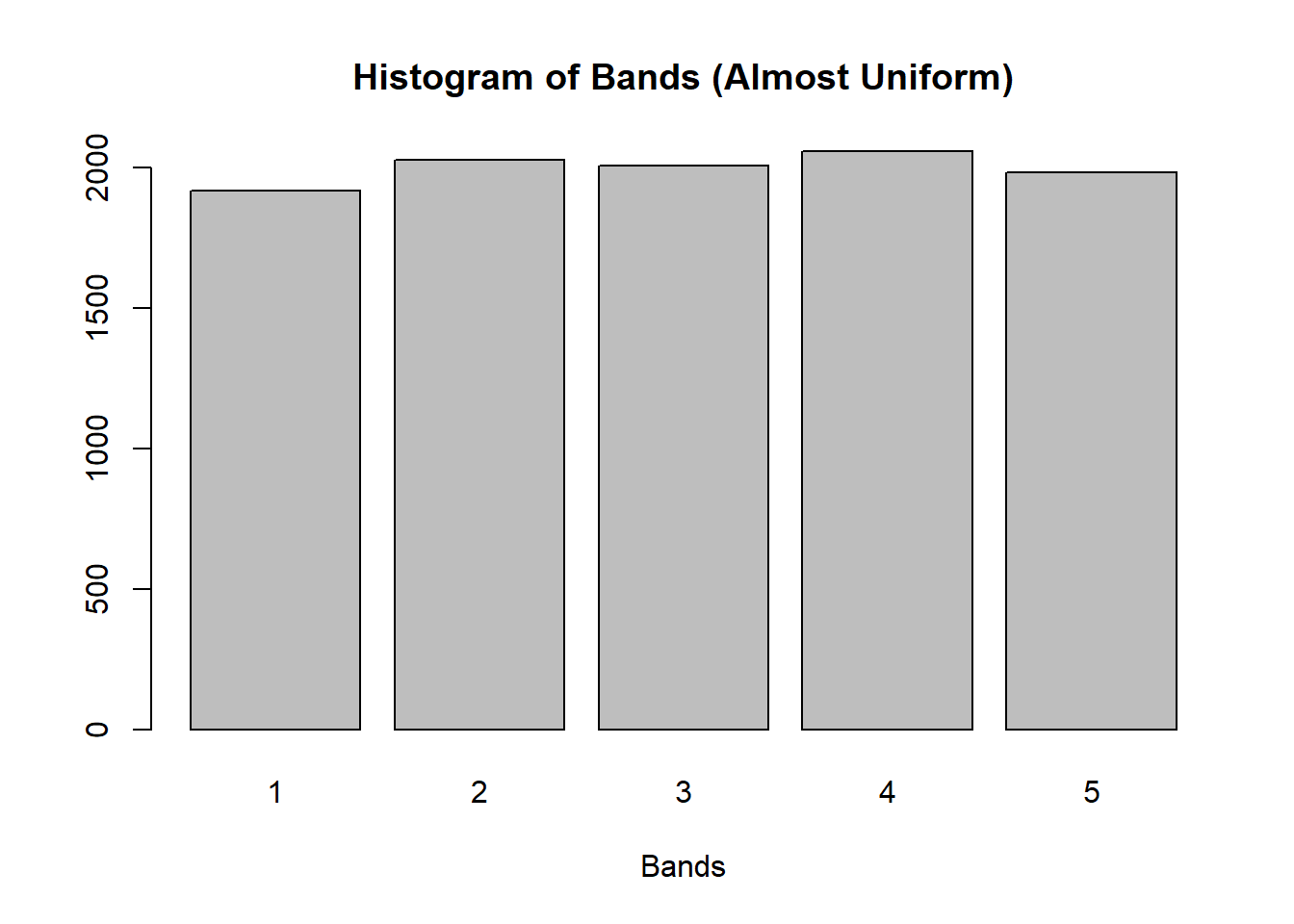
If we use a uniform probability of p(x_{ij}) = 1/5 we will end up with a uniform distribution, but we desire a distribution that is skewed to the left. Remember that the bands are a proxy for the socio-economic status of the household, and in Kenya – as in most other countries3 – the number of rich households is significantly lower than the number of poor households, therefore we need to expect more band 1 households than band 5 households.
Code
# generate 5 bands via multinomial distribution with equal probabilitiesset.seed(44)sample1 <-rmultinom(n =1,size =10000,prob =rep(1/5, 5)) |>as.data.frame() |> dplyr::mutate(Counts = dplyr::row_number()) |> dplyr::rename(Summary = V1)# expand the Counts by Summarysample2 <-rep(sample1$Counts, sample1$Summary)# visualize resultsbarplot(table(sample2), xlab ="Bands", main ="Histogram of Bands (Almost Uniform)")
We could specify the 5 distinct probabilities p(x_{ij}) by trial and error, but the most effective way to get better probabilities is to think of each observation as a sum of 5 binomial trials (p(x) = (_x^n)p^xq^{n-x}) –not to be confused with multinomial – with the probability of success in each trial being p(x_{ij}) = 1/5. Each trial results in either a success (1) or a fail (0). Summing these outcomes, the lowest possible value will be 0 (all fails), and the highest will be 5 (all successes). Therefore, each student will be assigned a value between 0 and 5 (inclusive). As it turns out, 4s and 5s are significantly fewer than 0s and 1s, regardless of the seed value of the RNG. This is exactly what we want. Finally, declare x as an ordered factor because there is an intrinsic element of order or natural rank among the bands.
Code
# generate probabilities via 5 binomial trails with p = 1/5# 1 is added to remove band 0 and introduce band 5set.seed(44)prob <-prop.table(table(rbinom(n =10000, size =5, prob =1/5) +1)) # generate 5 bands via multinomial distributionset.seed(44)sample1 <-rmultinom(n =1,size =10000,prob = prob) |>as.data.frame() |> dplyr::mutate(Counts = dplyr::row_number()) |> dplyr::rename(Summary = V1)# expand the Counts by Summarysample2 <-rep(sample1$Counts, sample1$Summary)barplot(table(sample2), xlab ="Bands", main ="Histogram of Bands (Appropriately Positively Skewed)")
2.2 Gross Family Income
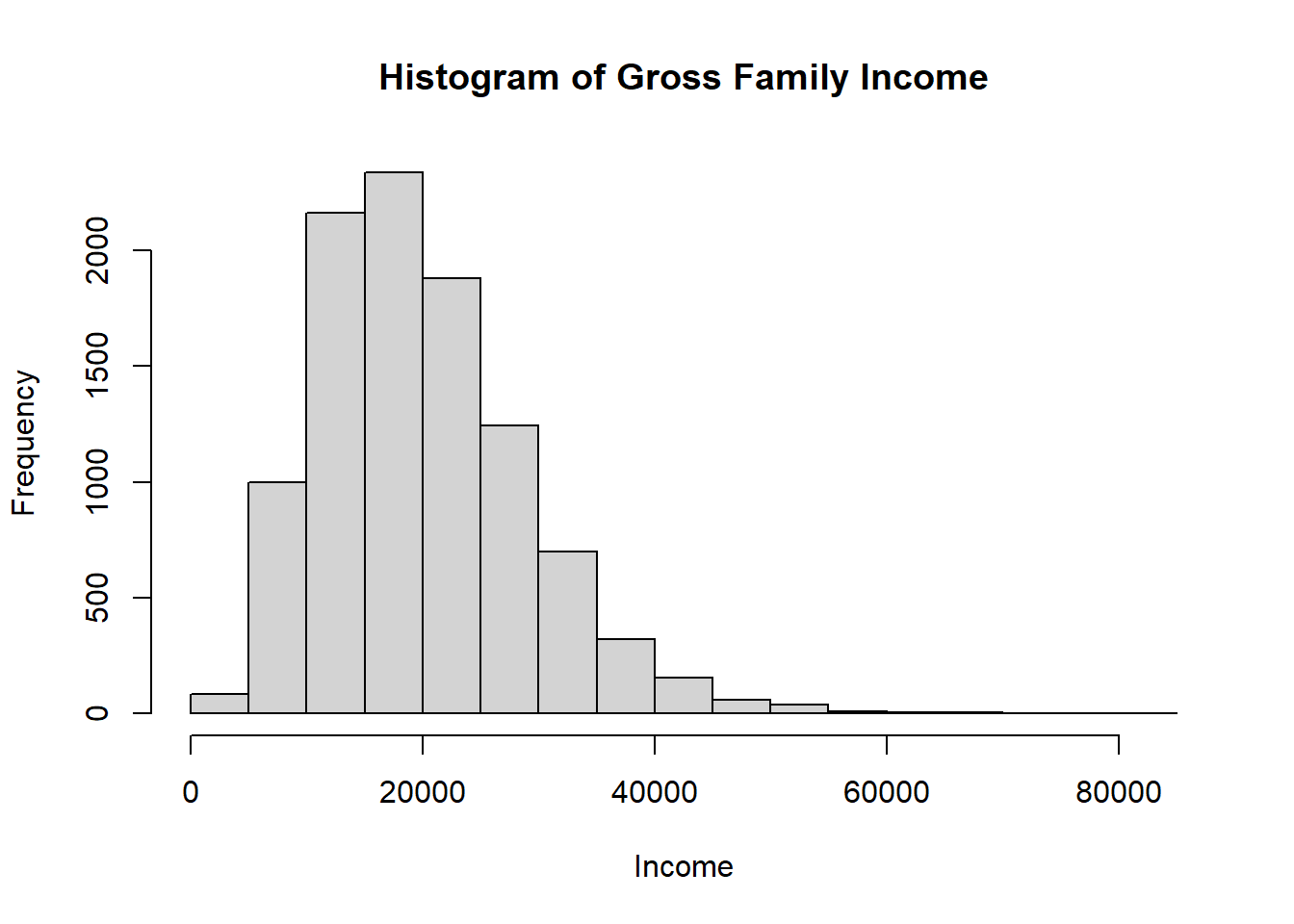
Income, as with bands, is expected to be a positively skewed real-valued number (x ∈ ℝ^+) which can assume the negative binomial distribution with the mean of KES 20,0004. From this knowledge we can generate 10000 income values using rnbinom function from the package {stats} as shown in the code below;
Code
set.seed(44)hist(rnbinom(n =10000, size =5, mu =20000), xlab ="Income", main ="Histogram of Gross Family Income")
2.3 Geographical Location
We will take all the 47 counties as the distinct geographical locations from which a student is equally likely to come – although realistically, certain counties have a relatively bigger share of student population, but for simplicity, we shall ignore this fact. With that out of the way, the appropriate probability distribution that ensures each student is allocated equal probability of being drawn from any of the 47 counties is the discrete uniform distribution. We can then simulate this variable using the function runif from the package {stats} as follows;
Code
set.seed(44)barplot(table(ceiling(runif(n =10000, min =1, max =47))), xlab ="Geographical Location", main ="Discrete Uniform Distribution of Geographical Location")
2.4 Poverty Probability Index
We shall treat this as x \sim N(\mu, s) which is in the field x ∈ ℝ^+. This is the so-called normal distribution, and both \mu and s are the mean and standard deviation apriori parameters. The probability density function itself is written as f(x) = \frac{1}{\sigma \sqrt(2 \pi)}e^{\frac{-1}{2}(\frac{x-\mu}{\sigma})^2}. According to the PPI tool, the mean index poverty for Kenya is approximately 0.3 and the standard deviation is approximately 0.2. With this apriori knowledge, we can plug the values into the rnorm function in the package {stats} as follows;
Code
set.seed(44)hist(abs(rnorm(n =10000, mean =0.3, sd =0.2)), xlab ="Poverty Probability Index", main ="Normal Distribution of Poverty Probability Index")
2.5 Orphans
This is a binary variable which indicates whether a student is an orphan or not, and therefore follows a binomial distribution with one trial (also called Bernoulli). We require the probability (rate/prevalence) of the status of being an orphan in Kenya for us to simulate the data for this variable. According to Lee et al. (2014), 22.2% of children aged 15 to 17 were orphans and vulnerable (OVC). Students joining university are mostly aged 17 to 20 years. We shall therefore use the rate of 0.222 to simulate this variable as shown below;
Code
set.seed(44)barplot(table(rbinom(n =10000, size =1, prob =0.222)), xlab ="Orphan Status", main ="Bargraph of the Distribution of Orphan Status")
2.6 Disability
This is yet another binary variable which indicates whether a student has disability or does not, and therefore follows a binomial distribution with one trial. We shall use the rate of 2.2%5. Plugging this value in the rbinom formula, we get;
Code
set.seed(44)barplot(table(rbinom(n =10000, size =1, prob =0.022)), xlab ="Disability Status", main ="Bargraph of the Distribution of Disability Status")
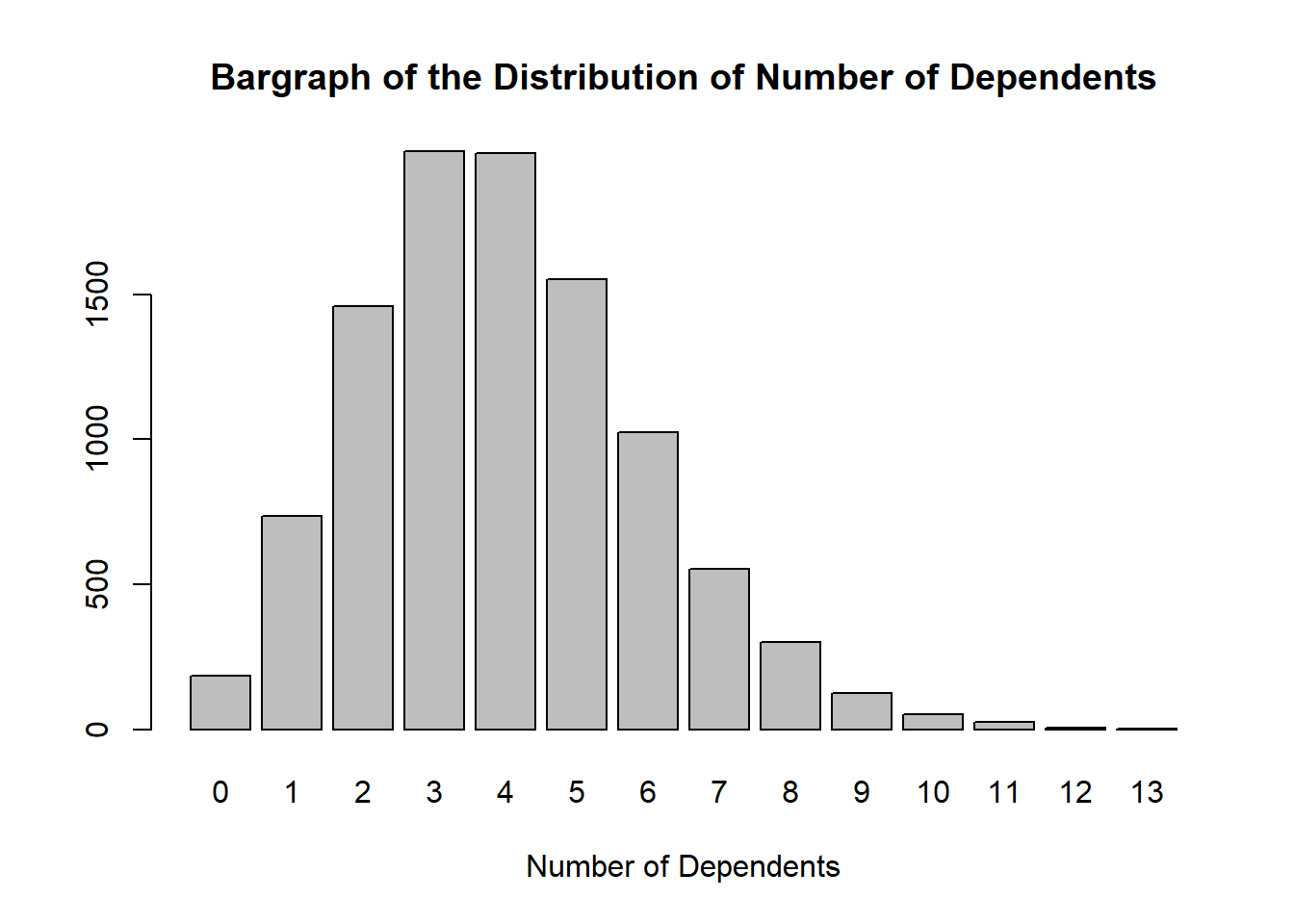
2.7 Number of Dependents
The variable represents counts, and therefore x ∈ ℕ^+. Both Poisson and negative binomial distributions could model the variable effectively, but this time round we shall focus on the former. The probability mass function for Poisson distribution is given as f(x) = \frac{e^{–λ} λ^x}{x!} where λ is the parameter representing the average number of occurrences of a Poisson event per unit space or time. In this context, it is the number of dependents per household. We shall use 4 as the value for this parameter6 and plug into the function rpois in the package {stats} as follows;
Code
set.seed(44)barplot(table(rpois(n =10000, lambda =4)), xlab ="Number of Dependents", main ="Bargraph of the Distribution of Number of Dependents")
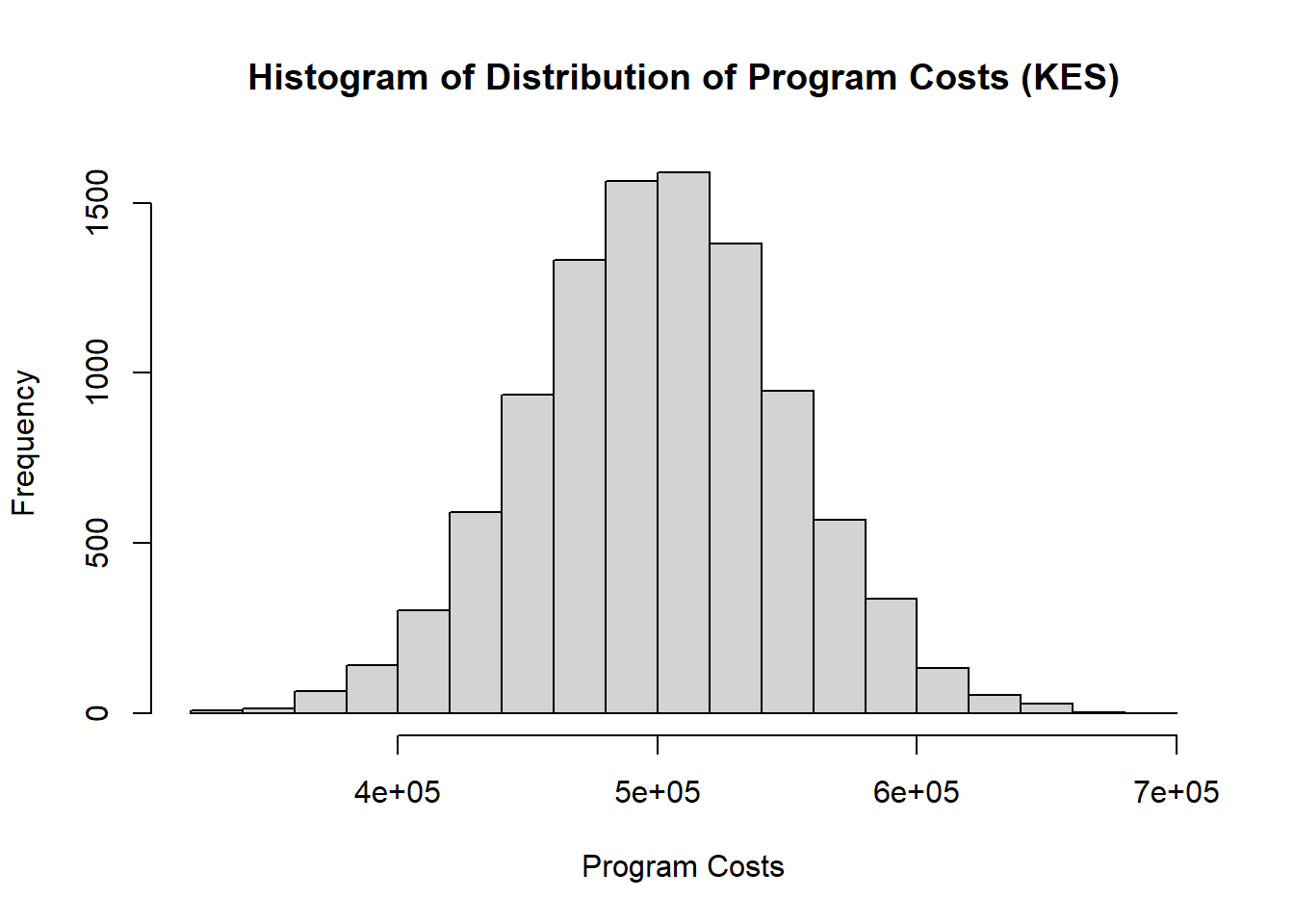
2.8 Program Costs (KES)
Similar to Section 2.4, this variable is in the field x ∈ ℝ^+ where x \sim N(\mu, s) with parameters taken to be \mu = 500,000 and s = 50,000. Feeding these values into the normal distribution RNG, we get;
Code
set.seed(44)hist(abs(rnorm(n =10000, mean =500000, sd =50000)), xlab ="Program Costs", main ="Histogram of Distribution of Program Costs (KES)")
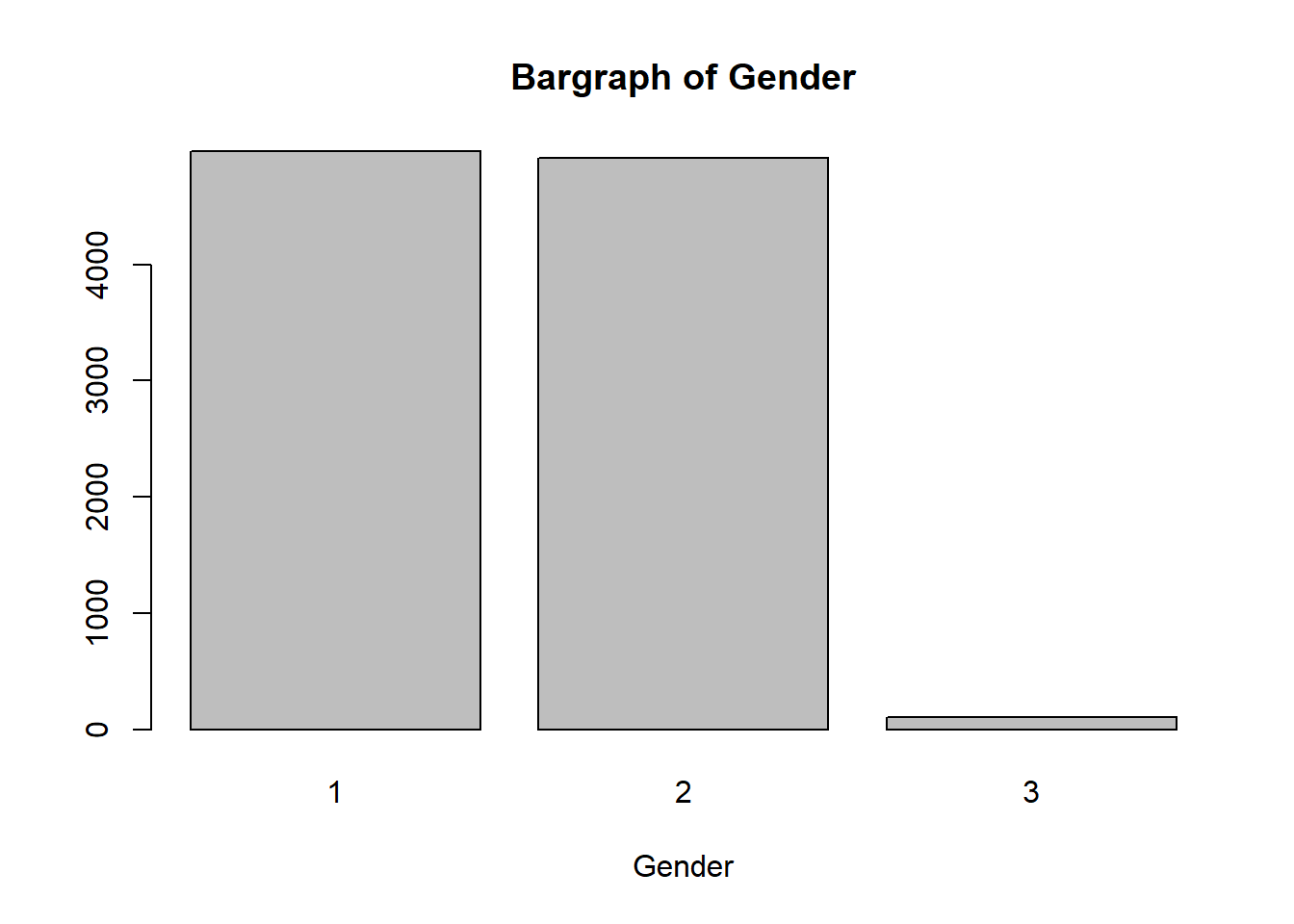
2.9 Gender
Similar to Section 2.1,this variable follows a multinomial distribution with 3 outcomes. This time round, we know the three probabilities p(x_{ij}) from literature; male (49.0%), female (50.0%), and intersex (0.01%)7.
Code
# declare probabilities (values gotten from existing literature)prob <-c(0.49, 0.50, 0.01)# generate 3 outcomes via multinomial distributionset.seed(44)sample1 <-rmultinom(n =1,size =10000,prob = prob) |>as.data.frame() |> dplyr::mutate(Counts = dplyr::row_number()) |> dplyr::rename(Summary = V1)# expand Counts by Summarysample2 <-rep(sample1$Counts, sample1$Summary)barplot(table(sample2), xlab ="Gender", main ="Bargraph of Gender")
3 Statistical Data Simulation
We shall use the following R packages (installed from CRAN) to simulate our variables;
Code
# load packageslibrary(here)library(tidyverse)
Now, let’s combine all the simulated data according to probability distributions and their associated parameters identified and considered in Section 2 into a data-frame. Notice that bands, gross family income, and PPI are sorted to ensure that households in lower bands (band 1) are correspondingly assigned lower gross income and higher PPI. The higher the PPI, the higher the likelihood that a household is considered poor. The rest of the variables must not be sorted.
Code
# table display setup#| label: tbl-simulated_data .striped .hover .primary .bordered#| tbl-cap: "Simulated data"#| tbl-cap-location: bottom ### bands# generate probabilities via 5 binomial trials with p = 1/5# 1 is added to remove band 0 and introduce band 5set.seed(44)prob_bands <-prop.table(table(rbinom(n =10000, size =5, prob =1/5) +1)) # generate 5 bands via multinomial distributionset.seed(44)bands1 <-rmultinom(n =1,size =10000,prob = prob_bands) |>as.data.frame() |> dplyr::mutate(Counts = dplyr::row_number()) |> dplyr::rename(Summary = V1)# expand the Counts by Summarybands2 <-rep(bands1$Counts, bands1$Summary)### gender# declare probabilities (values gotten from existing literature)prob_gender <-c(0.49, 0.50, 0.01)# generate 3 outcomes via multinomial distributionset.seed(44)gender1 <-rmultinom(n =1,size =10000,prob = prob_gender) |>as.data.frame() |> dplyr::mutate(Counts = dplyr::row_number()) |> dplyr::rename(Summary = V1)# expand Counts by Summarygender2 <-rep(gender1$Counts, gender1$Summary)### wrap everything up in a data-frame# for reproducibilityset.seed(44)simulated_data <-data.frame(# sorting is necessary Bands =sort(as.ordered(bands2), decreasing =FALSE),# sorting is necessaryGrossFamilyIncome =sort(rnbinom(n =10000,size =5,mu =20000), decreasing =FALSE),GeographicalLocation =as.factor(ceiling(runif(n =10000,min =1,max =47))),# sorting is necessaryPovertyProbabilityIndex =sort(abs(rnorm(n =10000,mean =0.3,sd =0.2)), decreasing =TRUE),Orphans =as.factor(rbinom(n =10000,size =1,prob =0.222)),Disability =as.factor(rbinom(n =10000,size =1,prob =0.022)), NumberOfDependents =rpois(n =10000,lambda =4),ProgramCostsKES =abs(rnorm(n =10000,mean =500000,sd =50000)),Gender =as.factor(gender2))# view data (printed on your browser)knitr::kable(head(x = simulated_data, n =5))
Bands
GrossFamilyIncome
GeographicalLocation
PovertyProbabilityIndex
Orphans
Disability
NumberOfDependents
ProgramCostsKES
Gender
1
1154
9
1.0563022
0
0
10
509734.8
1
1
2400
5
0.9868637
0
0
5
469997.6
1
1
2411
27
0.9790371
1
0
1
547886.0
1
1
2494
22
0.9679570
0
0
3
420495.4
1
1
2559
41
0.9642283
1
0
4
530990.7
1
We can finally save the simulated data in a desired location in the local computer disc for further use;
Code
# write data to discwrite.csv(x = simulated_data, row.names =FALSE, file = here::here("./Data/simulated_data.csv"))saveRDS(object = simulated_data, file = here::here("./Data/simulated_data.rds"))
4 Conclusion
We have covered a few ways in which data can be generated based on their known probability distributions, and the values of the parameters of those distributions obtained from existing literature.
Each probability distribution has a corresponding API, in the form of a function, that accesses the RNG. The API instructs the RNG to generate random numbers in a particular manner that satisfies the conditions of the probability distribution (pattern).
There are tens of other probability distributions that are outside the scope of this article. If you are interested in mathematical statistics, you may check them out. Each probability distribution describes a special phenomenon, with a wide range of real world applications.
However, the real world scenario may be too complex to be described by just one probability distribution, and in such a case, several distributions may be combined to create a complex (mixed) distribution that may sufficiently describe the real world scenario.